
HOW to ETL data from S3 Bucket to Redshift using IaC?

This post outlines the ETL process, focusing on Amazon Redshift and Dimensional Modeling. It covers data extraction from S3, transformation with a star schema, and loading into Redshift. Amazon Redshift features and Infrastructure as Code are introduced. The post concludes with a hands-on project for a music streaming startup, Sparkify, detailing data extraction, transformation, loading, and validation on Redshift.
What is ETL?
ETL stands for Extract, Transform and Load. It is the process of integrating data from many sources into a large central repository called data warehouse.
Extract: Extracting data from many sources (from AWS S3)
Transform: Transforming data by dimensional modeling
Load: Staging and load data designed by dimensional modeling to data warehouse (AWS Redshift)
What is Dimensional Model?
The dimensional data model provides a method for making databases simple and understandable.
Dimensional model is build on a star schema or snow-flake schema, with the main idea of dimension tables surrounding fact tables.
Star Schema is the simplest style of data mart schema. It consists of one of more fact tables referencing any number of dimension tables.
What is Amazon Redshift?
Amazon Redshift is a Columned-oriented Relational Database Management System. It is best suited for storing OLTP workloads.
Massively Parallel Processing (MPP) is one of Redshift features which help AWS Redshift achieves extremely fast query run. MPP executes one query on multiple CPUs or multiple machines in parallel where tables are partitioned and processed in parallel.
What is Infrastructure as a Code?
Infrastructure as Code (IaC) is the managing and provisioning of infrastructure through code instead of through manual processes.
The advantages of Infrastructure as Code over creating infrastructure manually:
Sharing: One can share all the steps with others easily
Reproducibility: One can be sure that no steps are forgotten
Multiple deployments: One can create a test environment identical to the production environment
Maintainability: If a change is needed, one can keep track of the changes by comparing the code
Hands-on project
Project introduction
A music streaming startup has grown their user base and song database and want to move their processes and data onto the cloud. Their data resides in S3, in a directory of JSON logs on user activity on the app, as well as a directory with JSON metadata on the songs in their app.
As a soon-to-be their data engineer, I am tasked with building an ETL pipeline that extracts their data from S3, stages them in Redshift, and transforms data into a set of dimensional tables for their analytics team to continue finding insights into what songs their users are listening to.
Hands-on
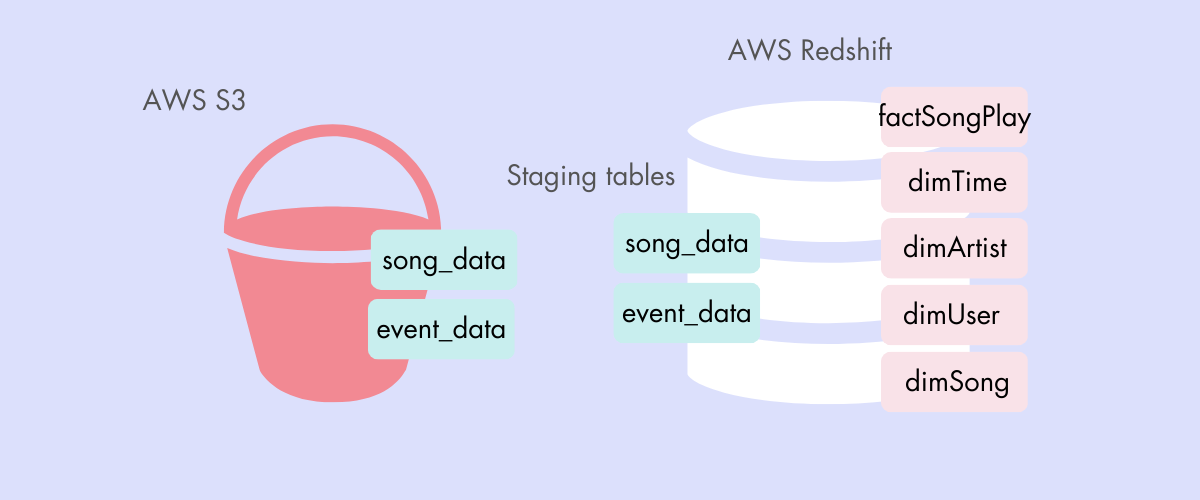
EXTRACT DATA FROM AWS S3 BUCKET
The raw data consists of two datasets stored in S3: song_data and log_data. Here are the S3 links for each:
Song data: s3://udacity-dend/song_data
Log data: s3://udacity-dend/log_data
Staging song and event tables are designed based on raw data, as below:
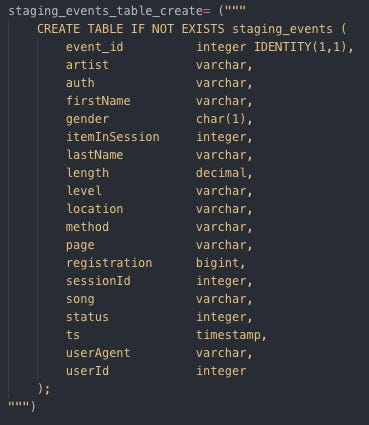
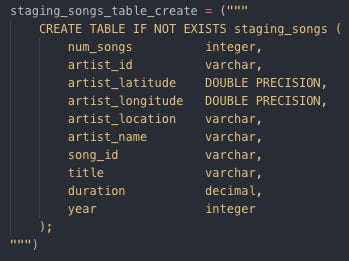
Staging event tables:
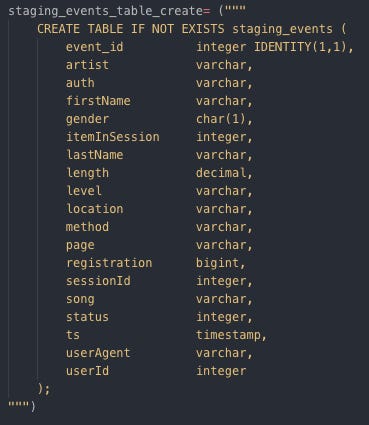
Creating staging event table by SQL Staging song tables:
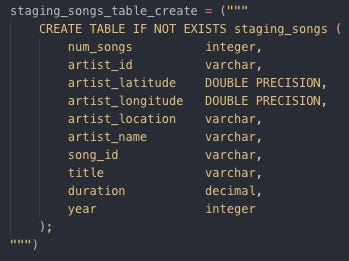
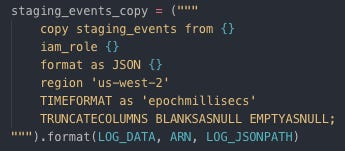
Creating Staging song table by SQL Copying raw data from AWS S3 to Bucket to staging tables created on Redshift
Copying data to staging event table
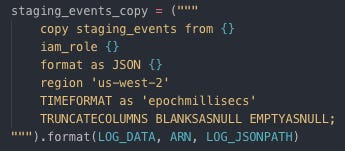
Copy raw data from S3 to staging event table on Redshift through Boto3 (SDK) Copying data to staging song table
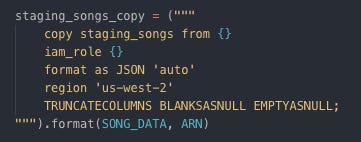
Copy raw data from S3 to staging song table on Redshift through Boto3 (SDK)
TRANSFORM DATA
Create tables following start schema dimensional modeling [Start Schema Design]
Create dimUser table

Creating dimUser by SQL table Create dimArtist table

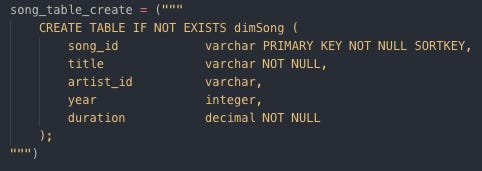
Creating dimArtist by SQL table Create dimSong table
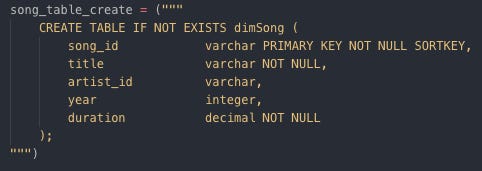
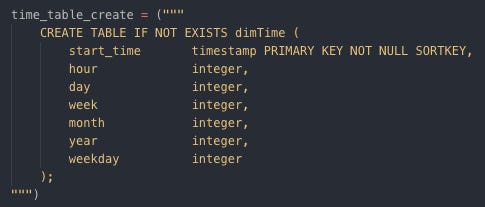
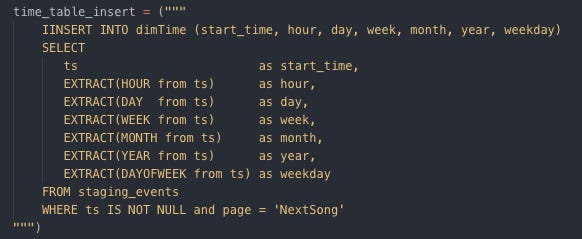
Creating dimArtist by SQL table Create dimTime table
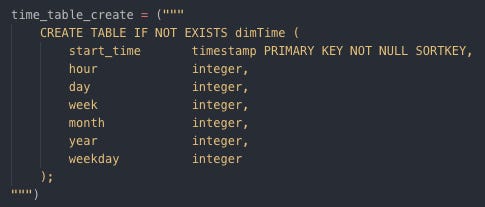
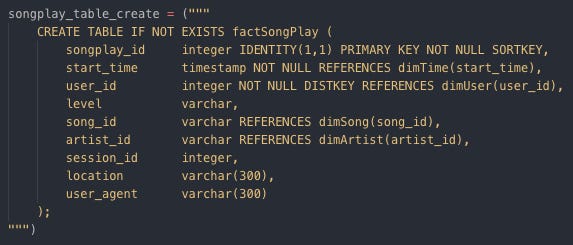
Creating dimTime by SQL table Create factSongPlay table
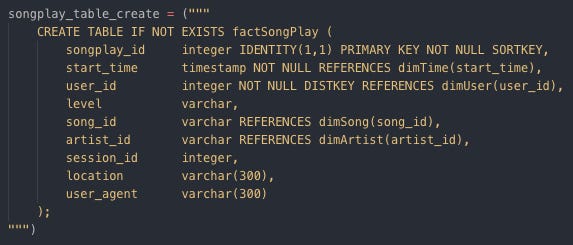
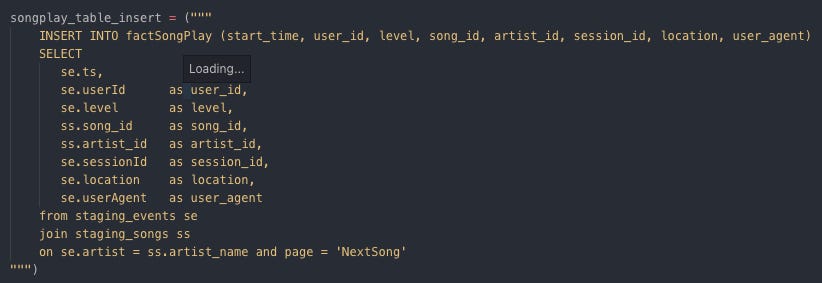
Creating factSongPlay by SQL table
Insert data from staging tables to start schema tables
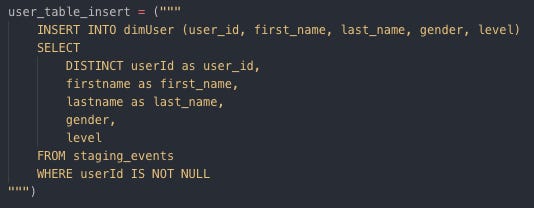
Insert data into dimUser
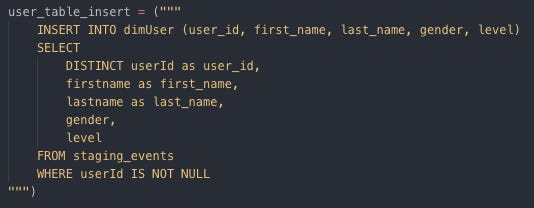
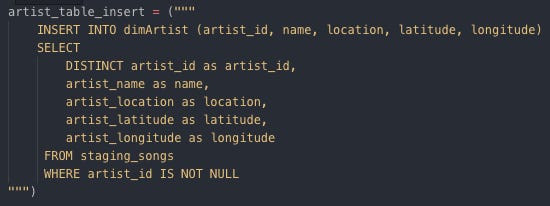
Inserting data into dimUser Insert data into dimArtist
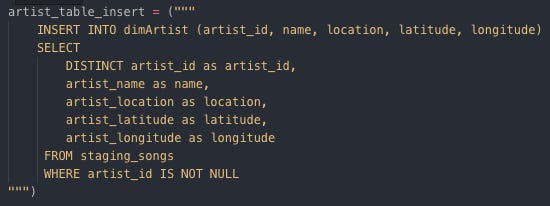
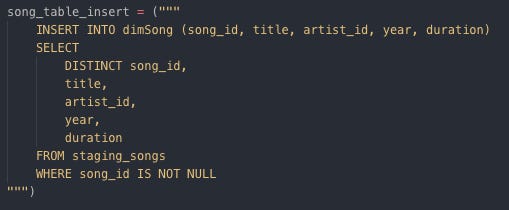
Inserting data into dimArtist Insert data into dimSong
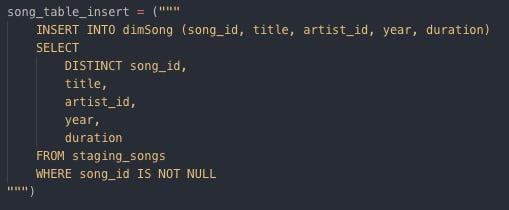
Inserting data into dimSong Insert data into dimTime

Inserting data into dimTime Insert data into factSongPlay
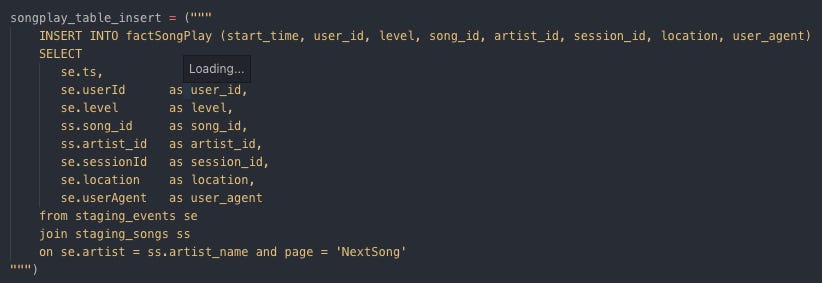
Inserting data into factSongPlay
LOAD DATA TO AWS REDSHIFT
Create clients and resources for IAM, EC2, S3, and Redshift

Creating clients and resources for IAM, EC2, S3 and Redshift Create IAM Role

Creating IAM Role Attaching Policy

Attaching Policy Creat Cluster

Creating Cluster Get Cluster Endpoint and ARN Role

Get Cluster Endpoint and ARN Role Connect to Cluster

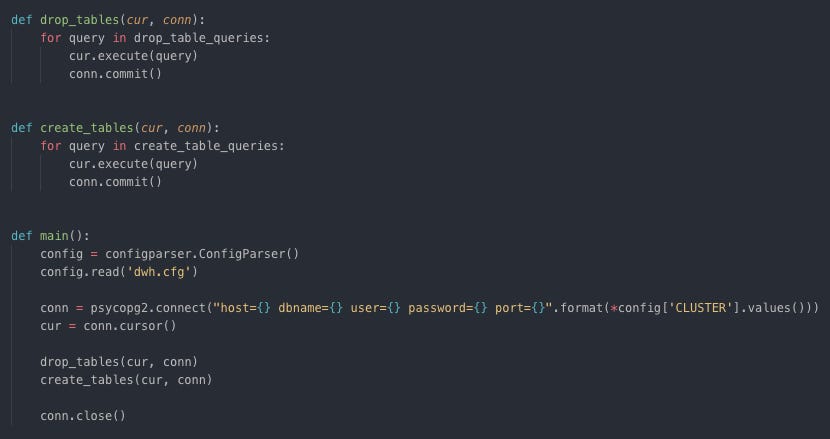
Connect to Cluster Create all staging and star schema tables
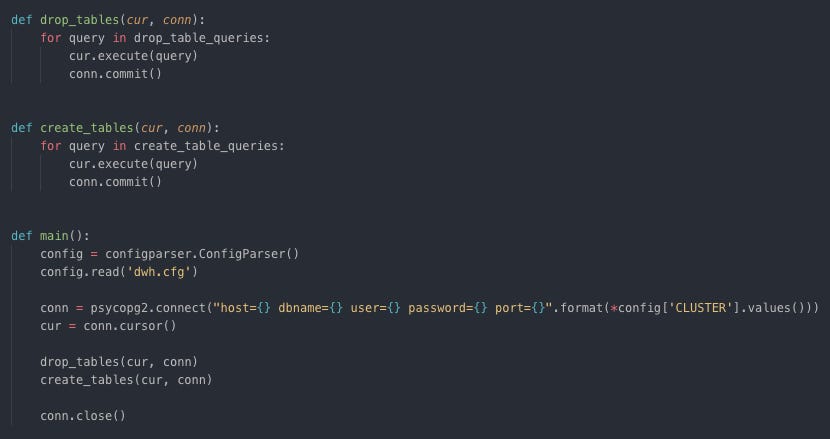
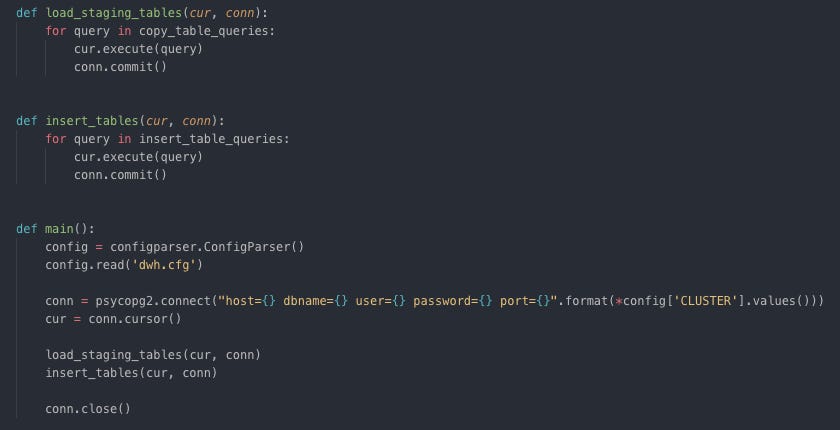
Drop if tables exist and create tables Load staging and insert star schema tables
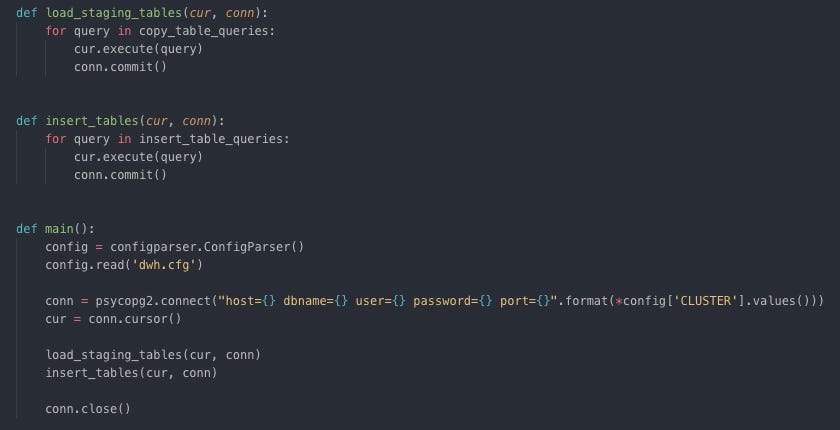
Copy and insert raw data from S3 to Redshift
VALIDATE DATA ON AWS REDSHIFT
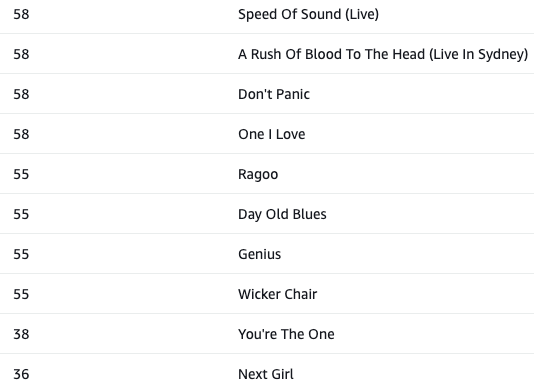
Top 10 songs
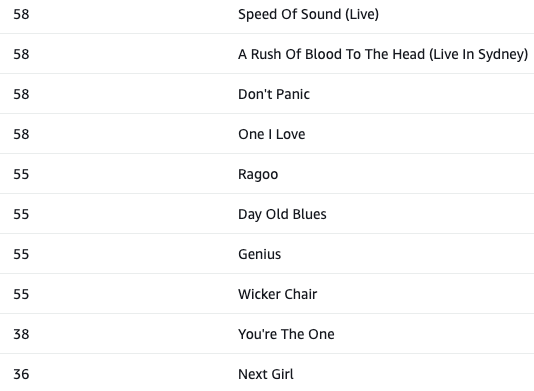
Top 10 songs








Conclusion
I just demonstrated how to ETL from AWS S3 Bucket to AWS Redshift by Infrastructure as a Code. By doing IaC, ETL process is easy to follow and maintain. If there is any errors during the building process, IaC can help you to verify the bugs easily and productively.
If you find this post helpful, please like, share, leave comment or subscribe for more content in the future. And as always, thank you so much for your interest in math, technologies and science.
Charlotte.